
一个计算任务从手机传到边缘服务器,传输耗时10毫秒,处理耗时50毫秒——按理说60毫秒就能搞定。但实际测下来,用户等了260毫秒。
多出来的200毫秒去哪了?排队。
这个看似不起眼的细节,在边缘计算领域被忽视了很久。芯片厂商拼算力,运营商拼带宽,算法团队拼优化策略,所有人都在想办法让任务”算得快、传得快”,却很少有人关心任务在队列里“等多久”。

河南科技学院人工智能学院的一个团队,偏偏盯上了这个问题。他们在《Scientific Reports》(《自然》旗下期刊)上发了篇论文,核心观点只有一句话:边缘计算的性能瓶颈,可能不在算力和带宽,而在队列管理。

这个判断听起来有点反常识。但如果你想想现实场景——几十个摄像头同时回传视频流、几百台AGV同时请求路径规划、上千个传感器同时上报数据——任务不是”即来即走”的,它们会在本地设备、邻近设备、边缘服务器的队列里排队等候。
传统的任务卸载算法在做决策时,根本看不到这些队列的积压情况。
这就像导航软件只告诉你”这条路限速80″,却不告诉你”前方堵车3公里”。你按最优路线跑过去,结果发现根本走不动。
被忽略的200毫秒
边缘计算的任务卸载问题,学术界研究了至少十年。主流思路是优化两个指标:处理延迟和能耗。
处理延迟好理解——任务在某个设备上算完需要多久。能耗也好理解——传输和计算要消耗多少电。
但还有第三个隐性成本:等待延迟。

王艳艳、孔德川、柴浩杰等研究人员在论文中指出,现有研究大多假设任务一到达就能立刻被处理,但实际情况是:
- 本地设备可能正在处理其他任务
- 邻近设备可能自己就有一堆活儿要干
- 边缘服务器可能同时服务着几十个用户
任务得排队。
对时延敏感型应用来说,这个排队时间可能比处理时间本身还致命。自动驾驶的毫秒级决策、工业机器人的实时控制、远程手术的同步操作——多等200毫秒,可能就是事故和正常运行的区别。
更要命的是,传统算法在做卸载决策时,完全不看队列情况。它只会算”这个任务在本地处理要60毫秒,卸载到边缘云要50毫秒,那就卸载”——但它不知道边缘云那边已经排了20个任务在等。
这就是河南科技学院团队想解决的问题。
让任务”看见”队列再做决定
团队提出的解决方案叫D-CCO算法(D2D-assisted Collaborative Computational Offloading,D2D辅助协同计算卸载策略)。核心思路是:把队列积压纳入卸载决策。
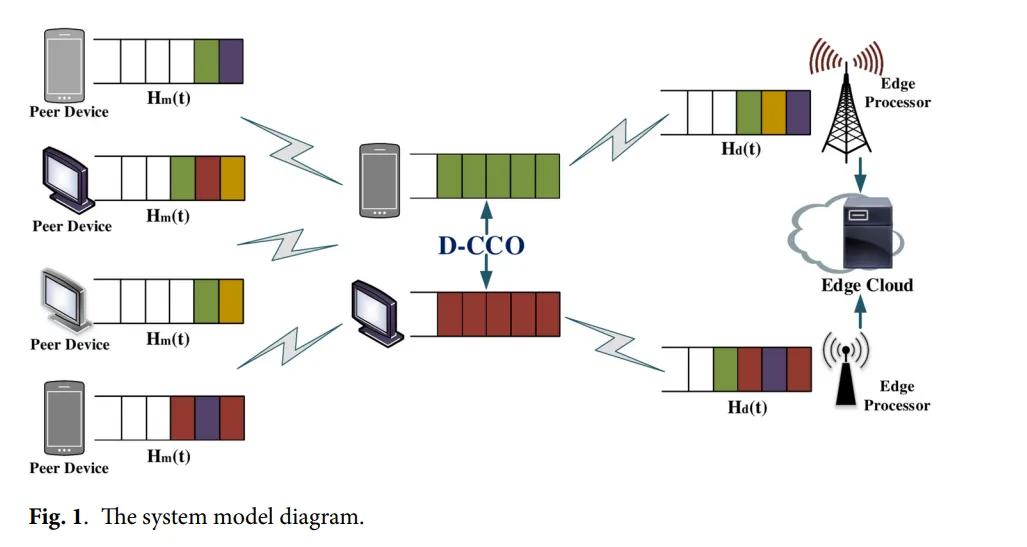
具体怎么做?分两步走。
第一步:算清楚三条路的成本
对每个到达的任务,算法会计算三种方案的总成本:
- 本地执行:处理延迟 + 能耗
- 卸载到邻近设备(D2D):传输延迟 + 处理延迟 + 能耗
- 卸载到边缘云:传输延迟 + 处理延迟 + 能耗
如果本地执行成本最低,任务留在本地;否则进入第二步。
第二步:用”反压算法”看队列情况
这是论文的关键创新。算法会实时计算本地队列与目标队列(邻近设备或边缘服务器)之间的”积压差”:
- 邻近设备队列积压少?优先卸载过去
- 边缘服务器队列积压少?卸载到边缘云
- 选择积压差最大的那条路径
用论文里的术语说,就是利用Lyapunov优化理论最小化队列长度,同时保证系统稳定性。论文在附录中给出了严格的数学证明,证明了所有队列都有上界,不会无限增长。
换成人话就是:任务会主动往”不堵”的地方流动。
实验数据:延迟降了,队列也稳了
团队在MATLAB R2019a环境中做了仿真,对比了六种算法的表现:
- OL(只本地执行)
- RD(随机卸载)
- BP(传统反压算法)
- OLP(只考虑本地和邻近设备)
- EPSO-GA(基于粒子群和遗传算法)
- D-CCO(本文方案)
实验设置:20个本地设备、10个邻近设备、1个边缘云处理器。每个设备100个任务到达,任务数据量500比特,边缘云频率35GHz。
关键结果:
1. 队列真的稳住了
三类队列(本地、邻近设备、边缘云)在迭代650-900次后都收敛到稳定值。这证明算法理论分析没问题——系统不会因为任务积压而崩溃。
2. 延迟确实降了
当任务到达率为10时,D-CCO的处理延迟比EPSO-GA低约12%,比传统反压算法低约18%。
3. 发现了一个反直觉的现象
当邻近设备数量从6增加到14时,延迟曲线出现了”先降后升”。原因是:邻近设备虽然传输快,但算力有限——任务都涌过去反而造成新的拥堵。
这个发现很有意思。D2D不是越多越好,关键看算力和队列的平衡。
4. 边缘云算力越强,优势越明显
当边缘云频率从25GHz提升到45GHz,D-CCO的延迟下降最明显。说明算法能有效利用边缘云的算力优势。

这项研究解决了什么问题?
从技术角度看,D-CCO算法的价值在于三点:
第一,补上了队列管理这块短板。
以前的卸载算法更像”事前规划”——根据任务特征和设备性能做决策,但不管执行时的实际情况。D-CCO相当于加了”实时路况播报”。
第二,给D2D技术找到了合理定位。
D2D(设备到设备通信)一直被认为是边缘计算的有效补充,但怎么和边缘云配合?什么时候该用D2D?论文的实验数据给出了答案:不是”越近越好”,而是要看队列积压和算力的平衡。
第三,提供了稳定性的数学保证。
论文用Lyapunov优化理论证明了队列上界。这在工程上很重要——你得保证系统在高负载下不会崩溃。
还有哪些问题没解决?
论文也有明显的局限:
1. 能耗分析不够细
论文提到”考虑了能耗”,但实验主要展示的是延迟数据。能耗和延迟往往是矛盾的——降低延迟可能需要提高传输功率。这个权衡没详细讨论。
2. 数据集是自己设的
任务到达服从泊松分布,但真实场景中任务往往是突发的、有潮汐效应的。算法在真实流量下表现如何,还需验证。
3. 安全性没提
D2D直连意味着数据在设备间直接传输,绕过中心节点。这在某些场景下可能带来隐私风险。
4. 算法复杂度没给
反压算法需要实时计算队列差值,在资源受限的边缘节点上,计算开销有多大?论文没给时间复杂度分析。
边缘计算进入”精细化调度”时代
往大了说,这类研究反映出边缘计算发展的趋势:从”能力下沉”到”智能调度”。
早期边缘计算主要解决”算力在哪儿”的问题——把云的能力下沉到边缘节点。这个问题基本解决了。
接下来要解决的是”任务该去哪儿”的问题。这不是简单的”本地or云端”二选一,而是一个涉及多节点、多队列、多约束的组合优化问题。
任务卸载正在从”静态规划”变成”动态调度”。
从产业角度看,这种精细化调度能力可能会成为边缘操作系统的标配。KubeEdge、OpenYurt这些平台,未来可能会内置类似的队列感知调度器。
不过,从实验室到产业落地还有很长的路。河南科技学院这个团队做的是基础研究,提供了一种思路。工程化实现还需要解决很多实际问题:如何低成本获取队列状态?如何处理网络抖动?如何应对恶意设备?
边缘计算的下半场,比拼的是毫秒级的决策智慧。
论文信息:
Wang, Y., Kong, D., Chai, H., Qiu, H., Xue, R., & Li, S. (2025). D2D assisted cooperative computational offloading strategy in edge cloud computing networks. Scientific Reports, 15, 12303.
DOI:
10.1038/s41598-025-96719-8
通讯作者: 柴浩杰
单位: 河南科技学院人工智能学院(河南新乡)
资助: 河南省科技项目(242102210050, 252102210114)、国家级大学生创新训练计划(202410467035)
感谢阅读,欢迎转发扩散!